今天在使用hexo时遇到一个问题,特在此记录一下。
在使用
local_search时,一直处于loading状态
有段时间发现hexo的search插件一直处于loading状态, 后来发现有一次提交的文件中带了一个不可见的特殊字符,导致search插件故障。 将该字符删除即可恢复正常。
如果你使用vscode编辑文章,建议使用插件Remove backspace control character。
今天在使用hexo时遇到一个问题,特在此记录一下。
在使用
local_search时,一直处于loading状态
有段时间发现hexo的search插件一直处于loading状态, 后来发现有一次提交的文件中带了一个不可见的特殊字符,导致search插件故障。 将该字符删除即可恢复正常。
如果你使用vscode编辑文章,建议使用插件Remove backspace control character。
使用os模块获取当前工作目录:
1 | import os |
Error: Looks like “https://kubernetes-charts.storage.googleapis.com" is not a valid chart repository or cannot be reached: read tcp 10.0.2.15:51126->172.217.160.80:443: read: connection reset by peer
执行helm init时失败,这个问题可以通过手动指定stable存储库为阿里云的存储库来解决。
注意,要确定tiller的版本号,可以使用helm version命令来查看版本号。
1 | helm init --upgrade -i registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.12.0 --stable-repo-url https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts |
ContainerCreating
当执行kubectl get pod -l app=xxx时,容器一直处于ContainerCreating状态,
使用kubectl describe pod xxx-xxx查看pod信息。
kubelet does not have ClusterDNS IP configured and cannot create Pod using “ClusterFirst” policy. Falling back to “Default” policy.
没有启动dns服务,使用命令microk8s.enable dns dashboard启动dns。
code = Unknown desc = failed pulling image “k8s.gcr.io/pause:3.1”: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
这是由于无法连接到国外服务器造成的,可以先从国内的服务器上拉取相应的镜像,然后修改成相应的版本即可。
Importing test library ‘Selenium2Library’ failed: ImportError: No module named ‘Selenium2Library’
安装seleniumlibrary时需要注意有两个包,robotframework-seleniumlibrary和robotframework-selenium2library。
1 | pip install robotframework robotframework-seleniumlibrary |
WebDriverException: Message: ‘geckodriver’ executable needs to be in PATH.
找不到geckodriver,使用brew install geckodriver命令安装。
Ambari是创建、管理、监视 Hadoop 的集群的工具,这里的 Hadoop 是广义,指的是 Hadoop 整个生态圈(例如 Hive,Hbase,Sqoop,Zookeeper 等),而并不仅是特指 Hadoop。 简单来说,Ambari 就是为了让 Hadoop 以及相关的大数据软件更容易使用的一个工具。
Vagrantfile文件内容如下:
1 | # -*- mode: ruby -*- |
vagrant up之后,使用vagrant ssh ser连接到ser主机,
使用root身份运行ambari-server setup命令配置ambari服务信息,
完成之后使用浏览器访问http://your-host:8080,使用admin/admin登录。
更详细的信息可参考:Deploy_and_Configure_a_HDP_Cluster
Centos安装Ambari服务非常简单,执行下面命令即可:
1 | # Ambari Server |
Ambari Server安装完成之后可使用浏览器访问http://your-host:8080,使用admin/admin登录。
注意:在配置集群之前需要先设置后各主机的hostname,否则后面添加agent有可能会找不到server。
更详细的信息可参考:Deploy_and_Configure_a_HDP_Cluster
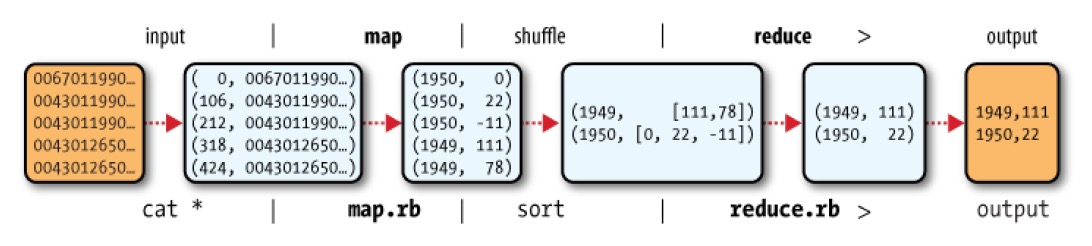
input:将数据转换成map的输入;map:处理输入的数据,每一行输入处理之后得到一行输出,输出是一个key-value格式的数据;shuffle:将map得到的数据按key进行组合,最后得到一个key-values的数据;reduce:将每一个key对应的values进行处理,得到结果key-value2;output:输出结果。这里需要理解的一个事情是,value的数据类型不仅仅是int,它可以是任意类型,包括数组。
1 | version: '2' |
查询时区
1 | select * from pg_timezone_names; |
格式化时间
1 | -- 格式化当前时间 |
反格式化时间
1 | -- 获取当前时间的0点 |
日期计算
1 | select now() - '1 month'::interval; -- 1月前 |