这两天做代码审查时,发现一处celery错误的用法。 他现在的做法是将一类任务通过计算hash值的方式,手动分配到多个队列中,然后每个队列起一个worker处理任务:
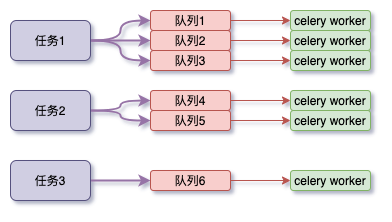
- 手动分配队列,首先代码的复杂度提升,其次编写代码的时候需要保持对队列使用的高度关注,再次,后期代码维护时极有可能遗忘这里关于队列的特殊用法
- 手动分配会导致任务分配不均,极有可能出现一个worker始终处于繁忙状态,且任务一直在堆积中,而其他worker却处于空闲状态
- 后期提升workers的处理能力将会变得困难,需要修改代码
正确的做法是,一类任务使用一个队列,而根据这类任务量的大小,一个队列启动多个worker:
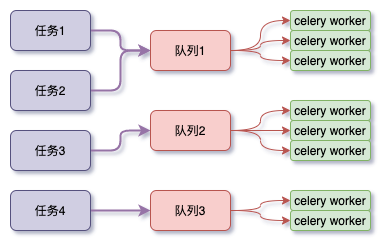
- 首先,代码会变得非常简单,只需要配置一个任务的队列即可
- 其次,多个worker处理一个队列,不会出现任务堆积的情况(假设workers总执行能力够的情况下)
- 最后,提升workers的处理能力变得简单,只需要针对这个队列再启动多个worker即可
其实,不仅仅celery队列可以这样,其他有关生产者-消费者模式的问题,都可以采用这一种方式处理。